本日、量子&AI耐性とECDSAのマルチシグならびに、ブロックチェーン機能拡張仕様 …
量子&AI耐性とECDSAのマルチシグならびに、ブロックチェーン機能拡張仕様が、mainnetで問題なく動作する点を確認できました!これで、ドライブ検査・復旧を含めた安全なネットワークを本格提供開始です。

SORA Integrate Wallet -> getkeyentangle()
[SORA] junkhdd.com / fromhddtossd.com / iuec.co.jp / web3dubai.io
本日、量子&AI耐性とECDSAのマルチシグならびに、ブロックチェーン機能拡張仕様 …
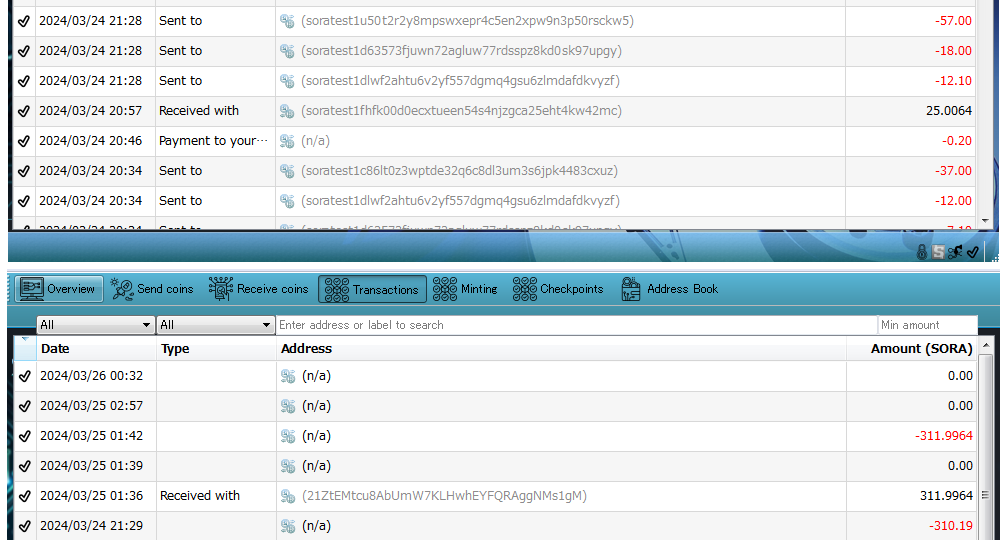
本日の画像は、古いノードから見た場合に、量子&AI耐性トランザクションを利用するウォレット …
The image today shows a wallet utilizing Quan …

私たちは現在、私たちは現在、一貫性チェックの最終段階です。ソフトフォークを採用しているため …
We are now at the final stage of the consiste …
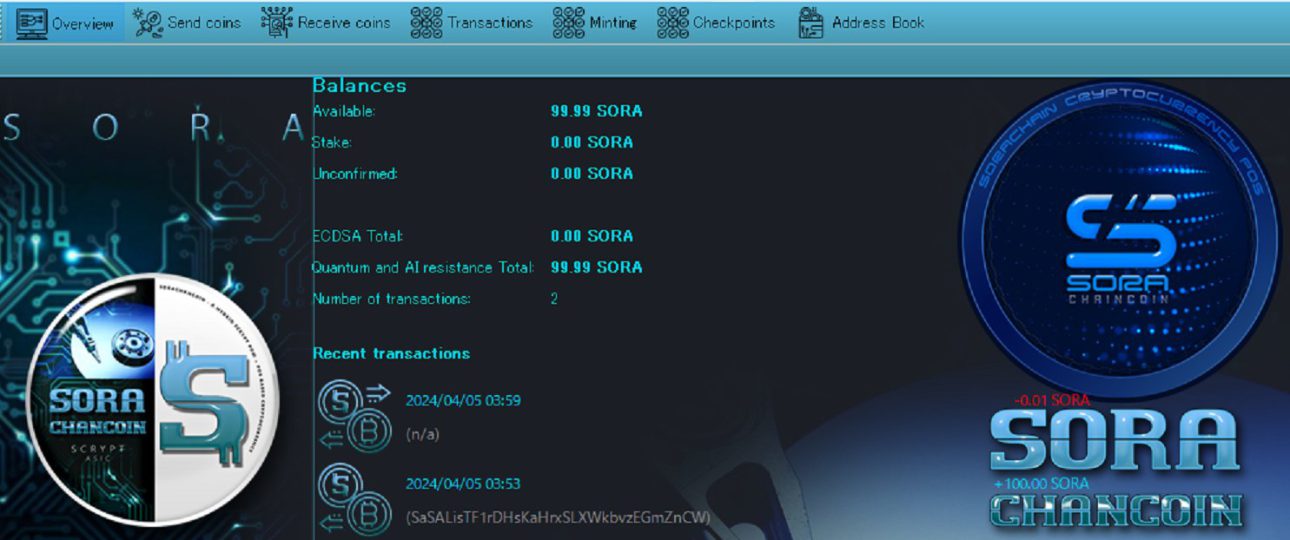
メインネット上で、量子&AI耐性を成功しました。 ECDSAを使用してコインを送信した後、 …
On the mainnet, we successfully achieved Quan …

量子&AI耐性はまもなく検証され、リリースされる予定です。その後、私たちも端末側での検証を …
Quantum & AI resistance will soon be vali …
マイニングプールと取引所向けの軽量版が完成しました。 https://github.com …
The lightweight version for mining pools and …
The mainnet release of Quantum & AI-resis …
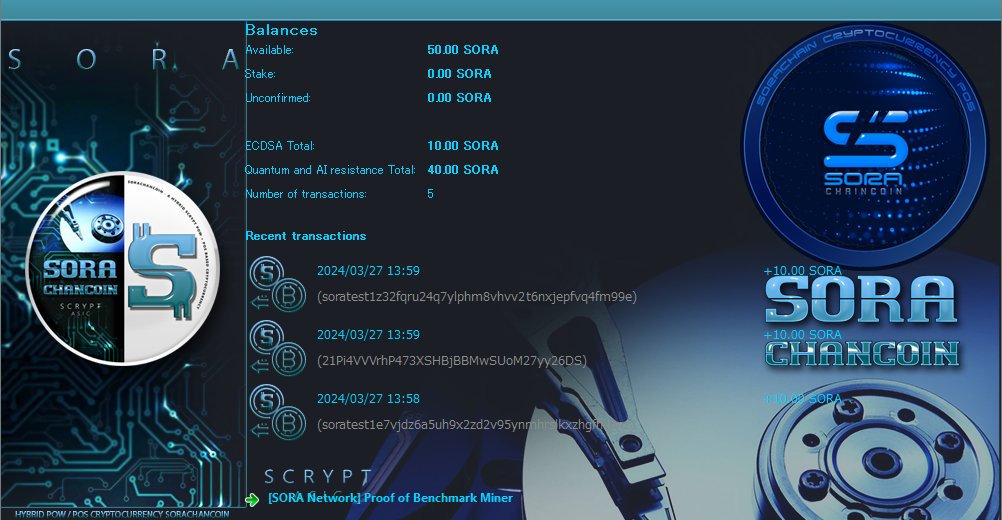
SORA L1のテストネットは順調に運用されています。これはテストネットなので、ECDSA …
The SORA L1 testnet is operating smoothly. Si …

本日、私たちはテストネットにデプロイしました。量子およびAI耐性トランザクションをお楽しみ …