We will improve the perspective and make full …
chapter248, [SORA][SORA Network] We have divided the source code into small units of translation.

SORA Integrate Wallet -> getkeyentangle()
[SORA] junkhdd.com / fromhddtossd.com / iuec.co.jp / web3dubai.io
We will improve the perspective and make full …
We will renew a commands(JSON-RPC) according …
In addition to the new hash (CQHASH65536), CS …
In order to reduce build errors, if there is …
A new logo has been created with the image of …
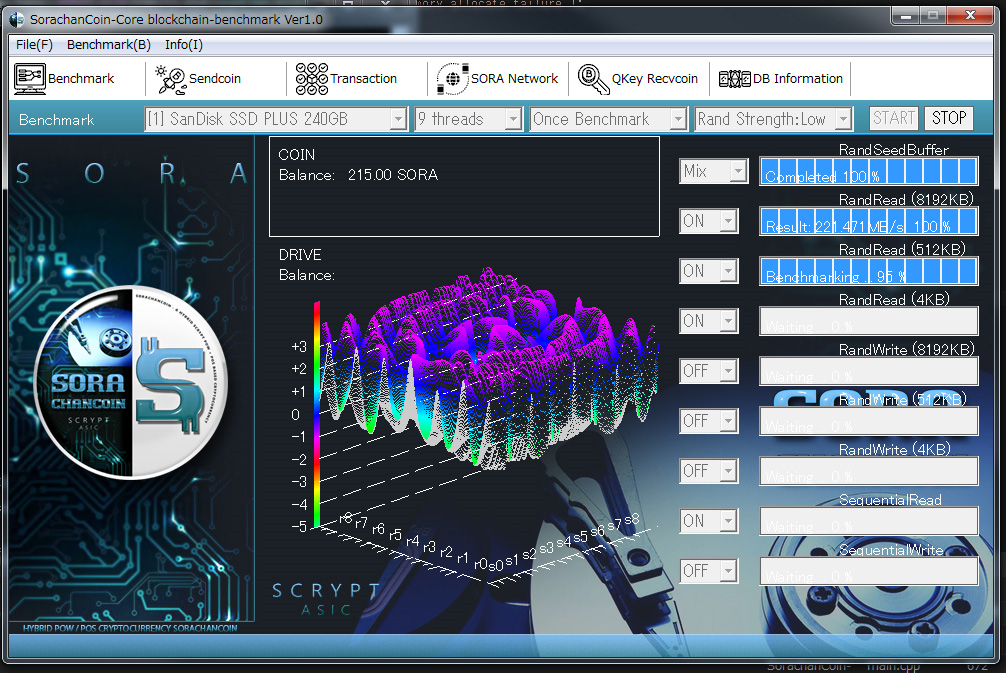
We can get Genesis with the new hash.Due to m …

We are currently making a new logo.It will be …

いつもお世話になっております。Hello friends!以下URLにある悪質な事例を、す …

いつもお世話になっております。Hello friends!以下URLにある悪質な事例を、す …

Finally, We were set free from FAX today!! In …
in preparation … https://driveinfo.junk …
Server maintenance has been completed. thanks …
“www.junkhdd.com” maintenance wil …
A search function is added. thanks! https://w …
The function of drive failure pre-detection h …