JSON and BitcoinRPC processing have been impr …
chapter263, [SORA][SORA Network] JSON and BitcoinRPC processing have been improved to “noexcept”.

SORA Integrate Wallet -> getkeyentangle()
[SORA] junkhdd.com / fromhddtossd.com / iuec.co.jp / web3dubai.io
JSON and BitcoinRPC processing have been impr …
We have removed an exception handler from the …
Obviously, the process of removing exceptions …
Due to the factor that were difficult to gras …
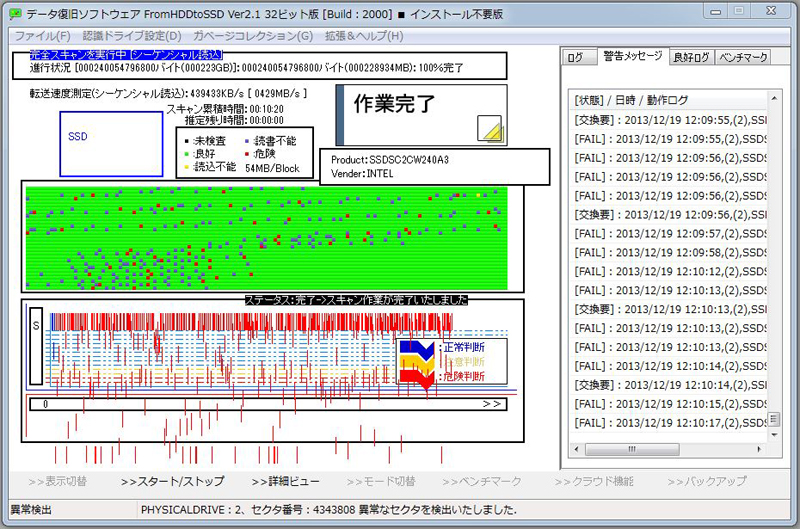
After the maintenance in October, we changed …
We implemented Softforks that will be carried …
This is implemented instead of getinfo.
The RPC command has been updated.It will be i …
We will intend three types of wallets accordi …
We have been updated the source code as the d …
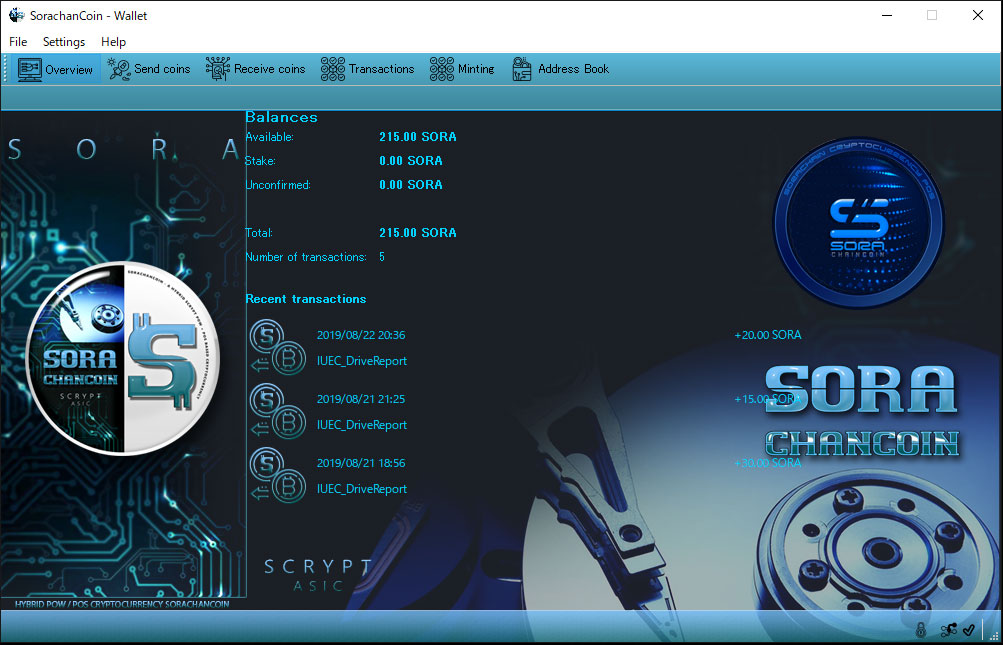
We will report these as the nodes are stable, …
1, Reference of new hashThis new hash is an e …
It definitely prevents a typing mistake in th …
On November 3, 2020, we will plan to release …
It is optional, but we answered today because …