いつもお世話になっております。開発担当の矢野と申します。開発状況や、アルゴリズム等について …
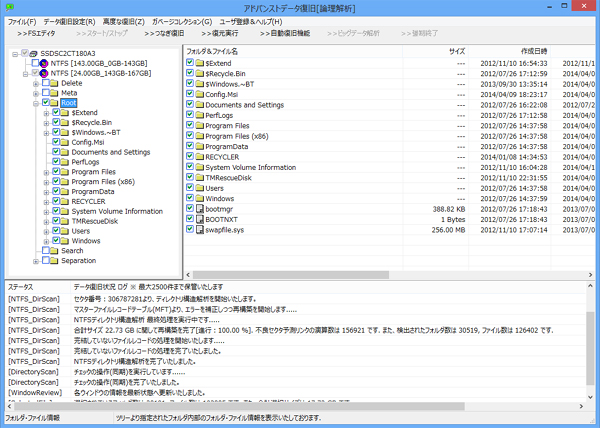
復旧不定期日誌135, 開発状況や、アルゴリズム等について日々まとめていきたいと思います
SORA Integrate Wallet -> getkeyentangle()
[SORA] junkhdd.com / fromhddtossd.com / iuec.co.jp / web3dubai.io
いつもお世話になっております。開発担当の矢野と申します。開発状況や、アルゴリズム等について …