いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 故障予 …
復旧不定期日誌109, [Lab]: 故障予測 パート8 (不良セクタの種類を考える1)
SORA Integrate Wallet -> getkeyentangle()
[SORA] junkhdd.com / fromhddtossd.com / iuec.co.jp / web3dubai.io
いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 故障予 …

いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 故障予 …
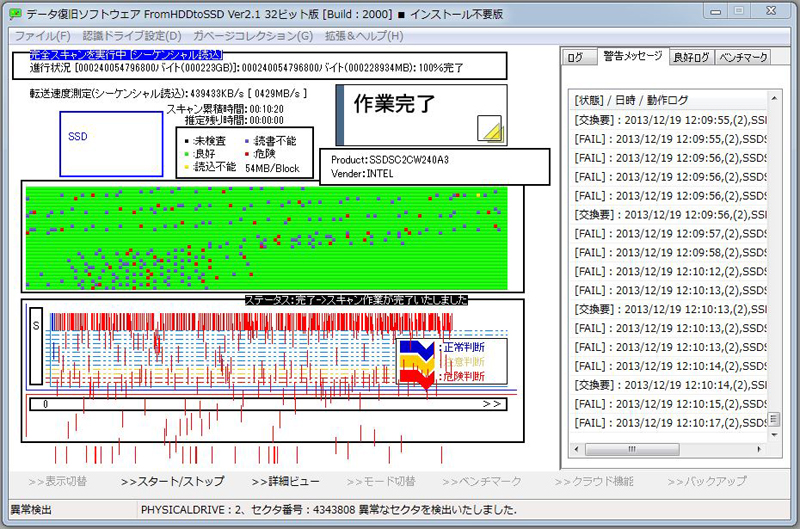
いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 故障予 …
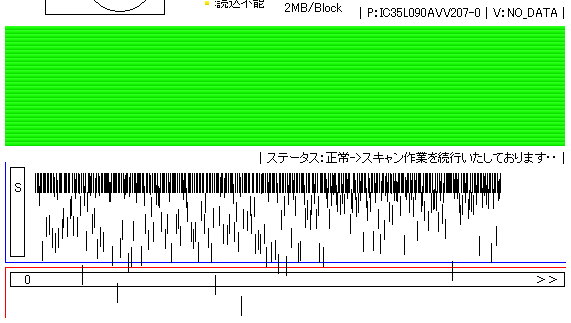
いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 故障予 …

いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 パート …
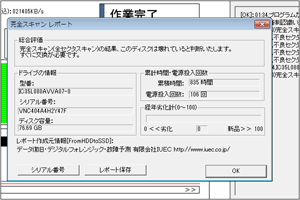
いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 パート …
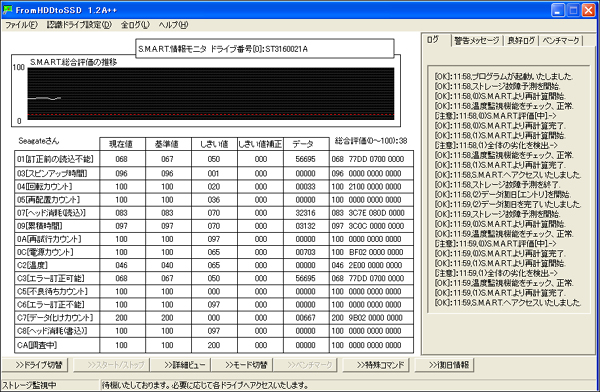
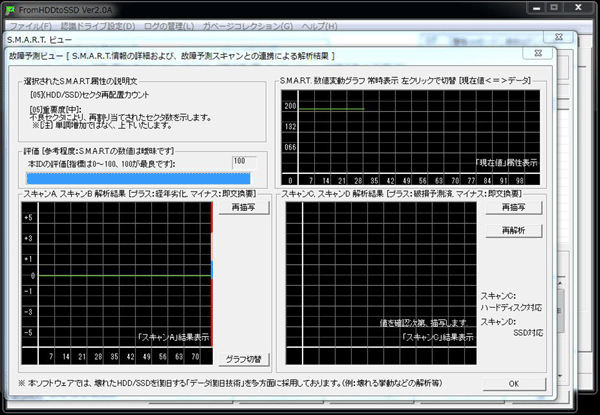
いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 パート …
いつも大変お世話になっております。データ復旧担当(現:故障予測)の矢野と申します。 シルバ …